
Increasing Message Throughput In Akka.NET Actor Systems
When you are building a real-time Actor System in Akka.NET, message throughput numbers will be one of your top engineering priorities. One wouldn’t be using a performance scalpel such as Akka.NET if speed wasn’t a main business concern. This article details four approaches you can use right now to improve the message processing and delivery throughput of your actor system.
Index
Routing
One of the main points of using Akka.NET is its ability to do some good old massively parallel processing for you at a unit of work level, far lower than at the process level of many other architectures.
Doing stuff in a serial manner? Break it down to the core and route it out.
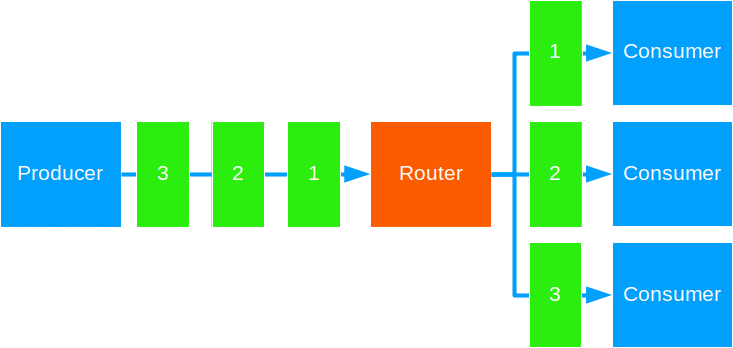
Routers allow you to distribute units of work across routees, in addition to a myriad of other use cases. Routers can send messages in-process, remotely or across a cluster. Some routers can even deploy new children in new nodes you add to a live cluster.
Router Families
There are two main families of routers in Akka.Net:
- Pool Routers
- Group Routers
This is how they compare:
| A Pool Router… | A Group Router… |
|---|---|
| Creates and uses its own routees as children | Routes to existing routees in the system or cluster |
| Supervises its own routees | Cannot supervise its routees |
| Can manage routee recovery | Has no control on routee recovery |
| Can only handle a single underlying props type at a time | Can route to any actor regardless of underlying props type |
| Can scale out its routee pool automatically | Has no control over scaling |
Router Strategies
A routing strategy decides which routee a router forwards a message to. Akka.NET ships with several in-built routers, covering different routing strategies. Most strategies are available for both Pool or Group router families, with some exceptions.
Round Robin
This strategy forwards messages to each target actor in a sequential fashion.
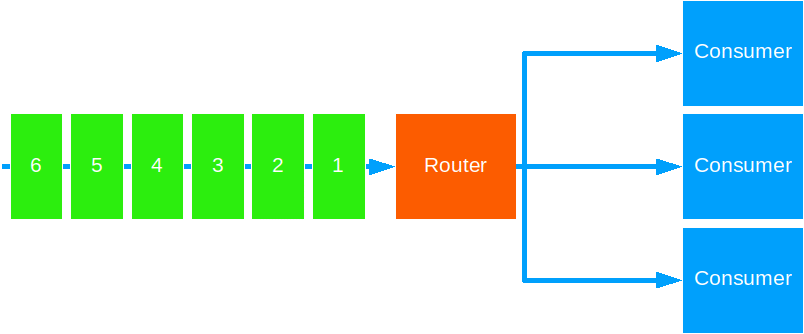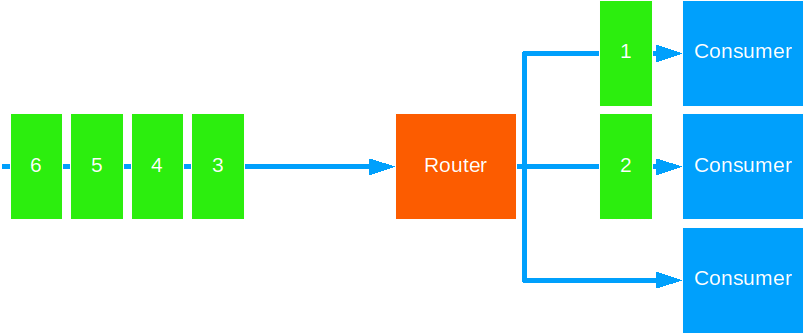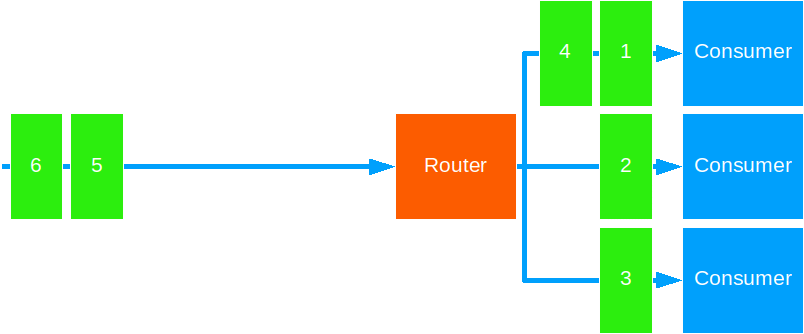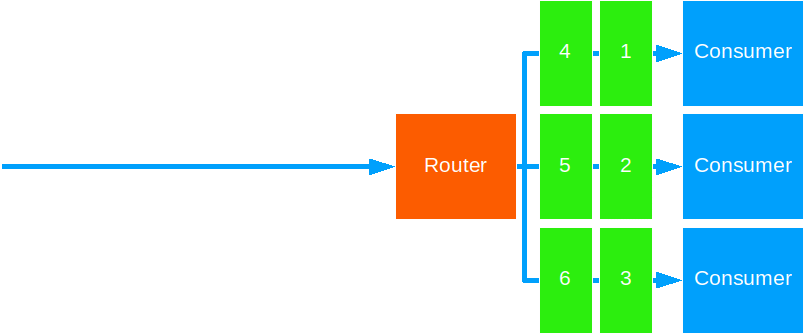
This is a good default strategy for most cases. Use this to distribute units of work that take equal time to complete.
Broadcast
This strategy forwards the same message to all target actors.
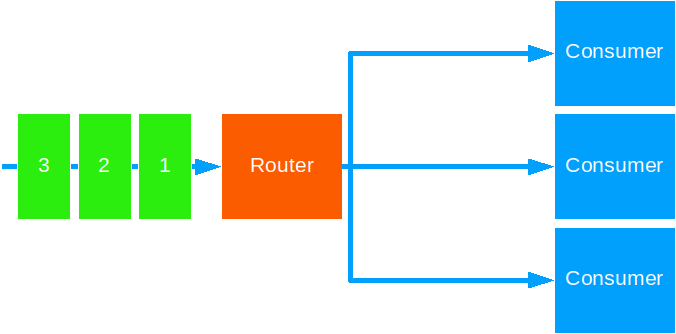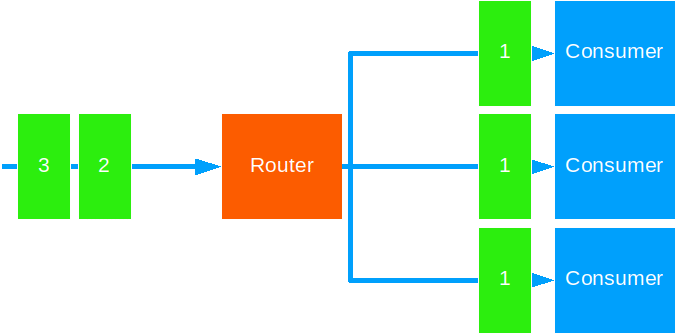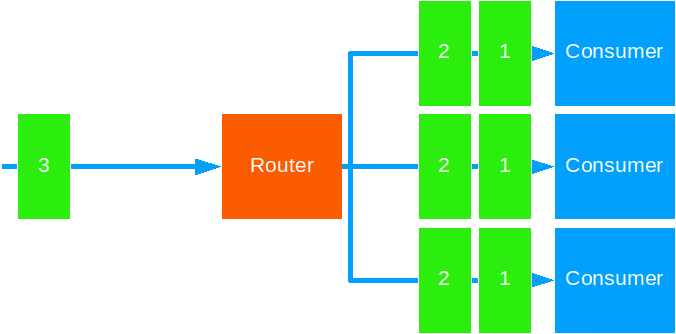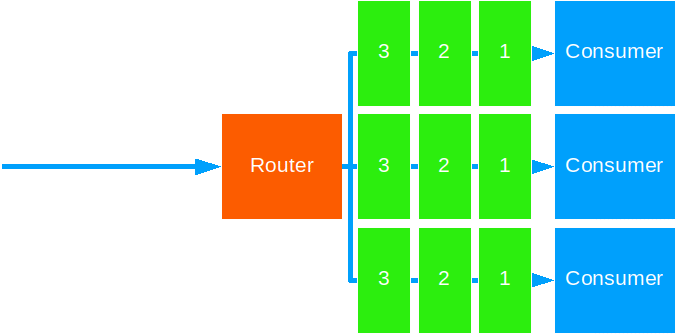
Use this when you need to notify all actors of some global event.
Random
This strategy forwards messages in random fashion.
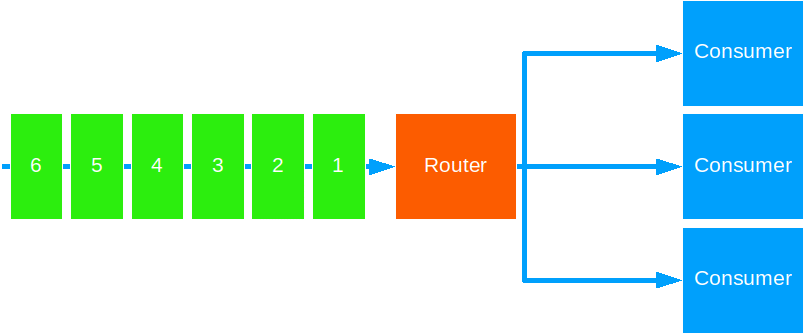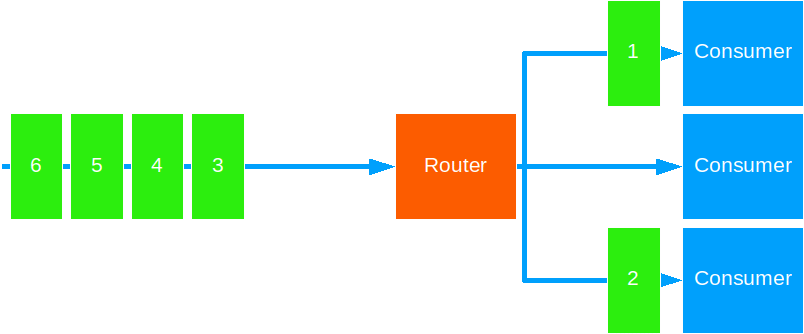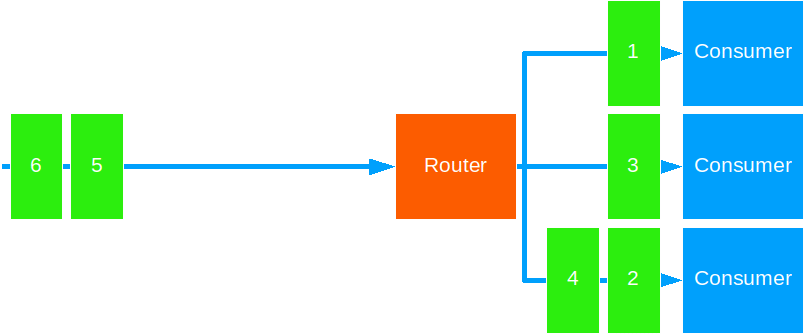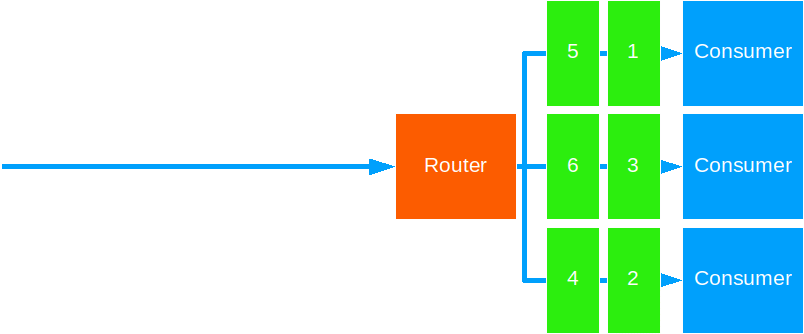
You can use this when:
- Distributing work with unknown completion time.
- Using a sequence of Round Robin routers is pushing many messages to a single routee.
However it is best to consider other options before resorting to random.
Consistent Hashing
This strategy forwards messages based on some key to the same target routee.
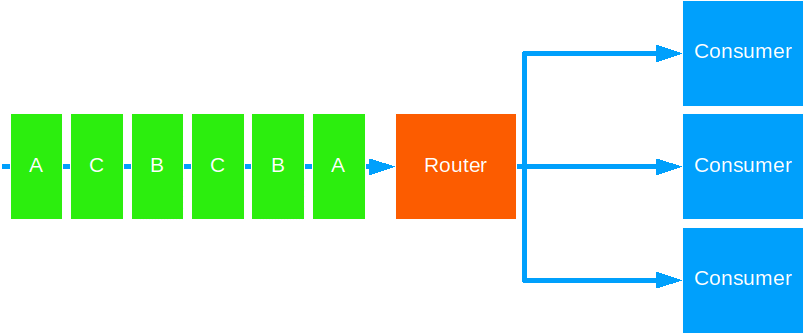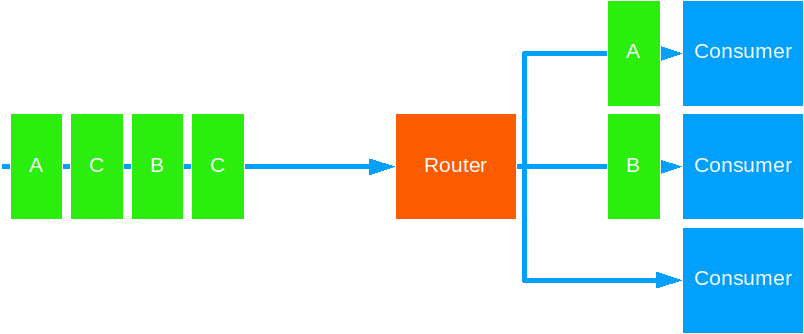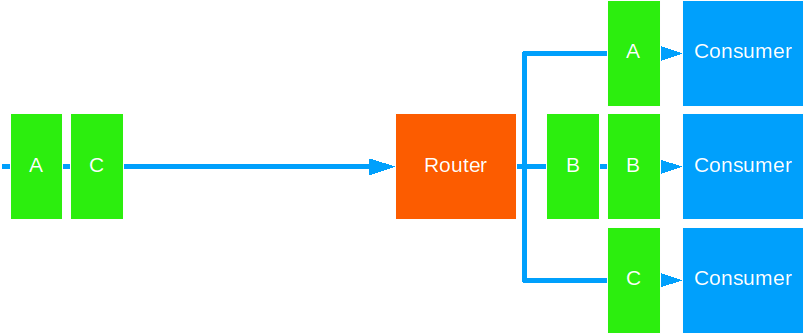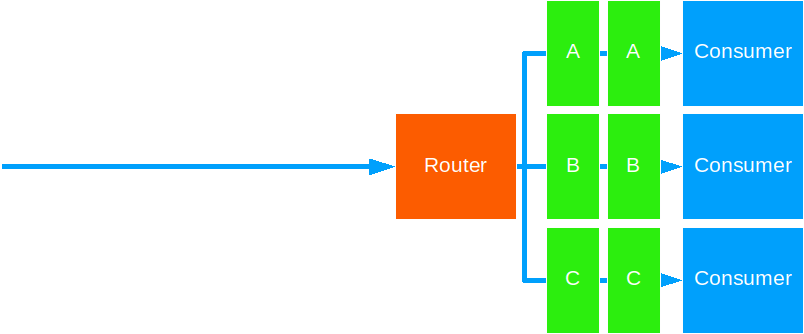
Use this to ensure ordered processing of messages for a given key.
Notes:
- The key is derived from some data in the message. You decide what the key is.
- The hashing and distribution algorithm is based on the key and the total number of routees. Therefore, if the pool/group size changes, the key to routee mapping will also change.
- A single target actor may receive more than one message type, should the distribution algorithm hash the key to the same value.
- Despite all the above, message delivery order is maintained.
Tail Chopping
This strategy keeps forwarding a given message to a random routee, until some routee sends a reply back. The reply is then handed to the original message sender. The strategy allows some time for a routee to reply before attempting the next one.
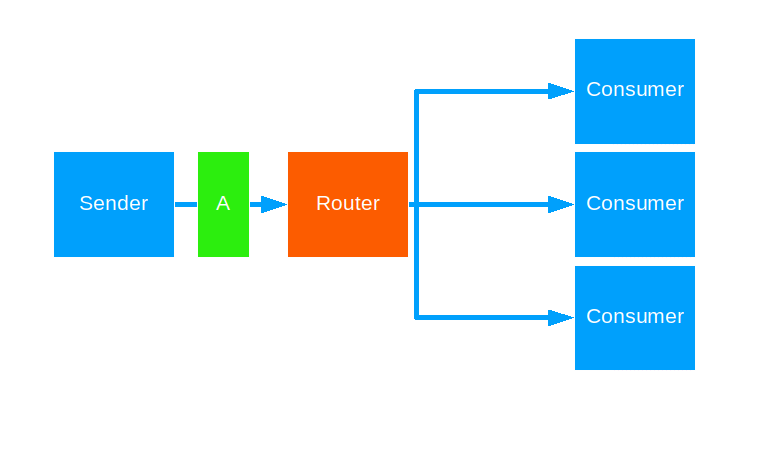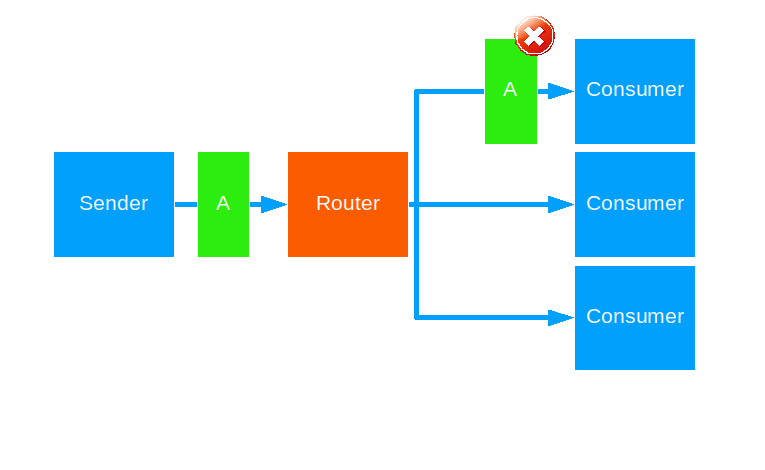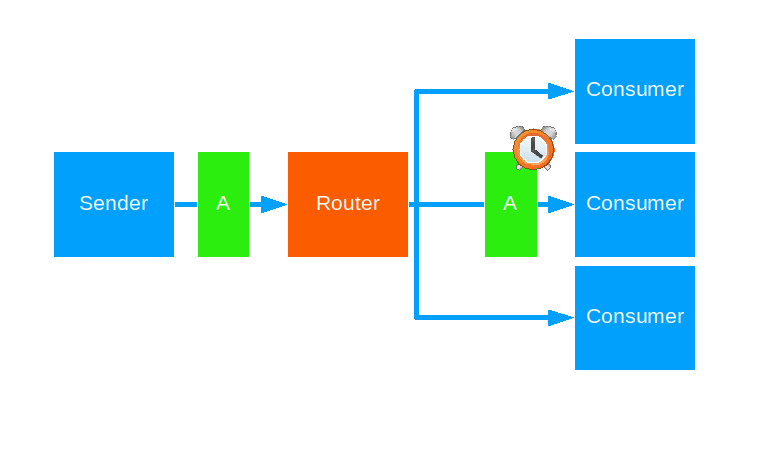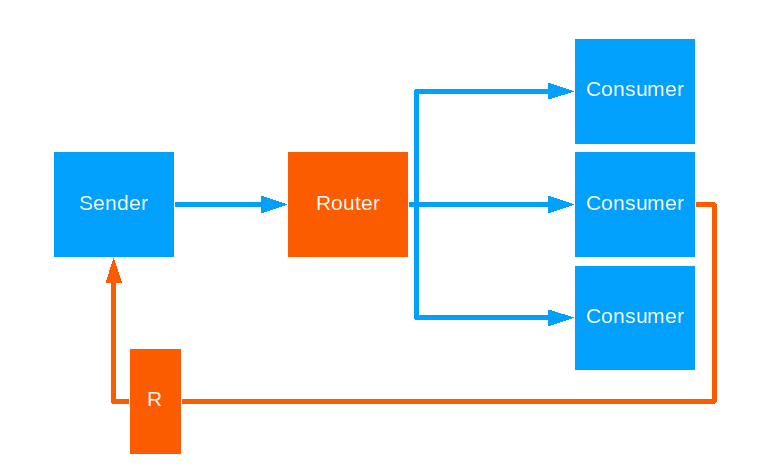
Use this when you want to brute-force a fast reply to the sender and have the resources to spare.
Notes:
- Any replies after the first one are ignored.
- To reduce too many wasted resources, have the routees implement some timeout of their own.
Scatter Gather First Completed
This strategy forwards a message to all routees - like broadcast - and forwards the first reply back to the original sender.
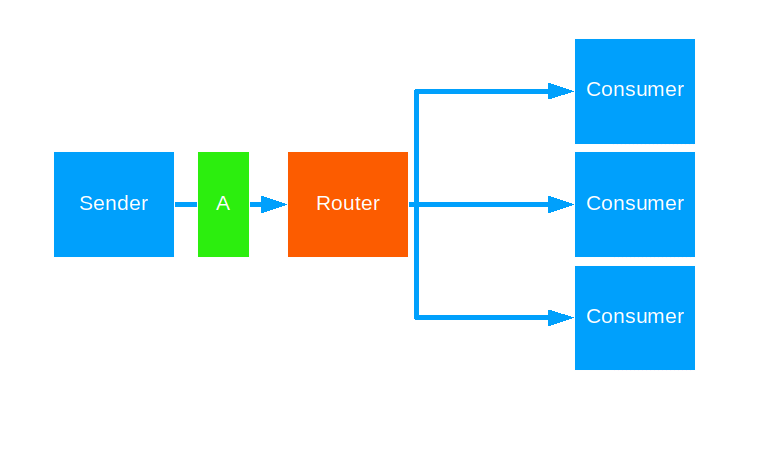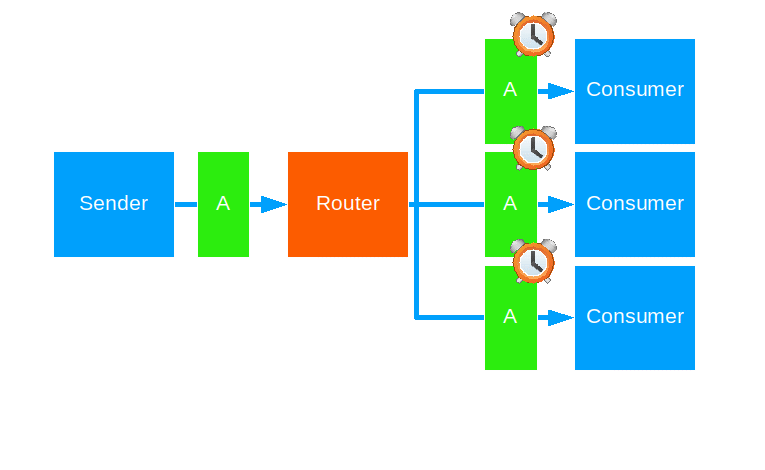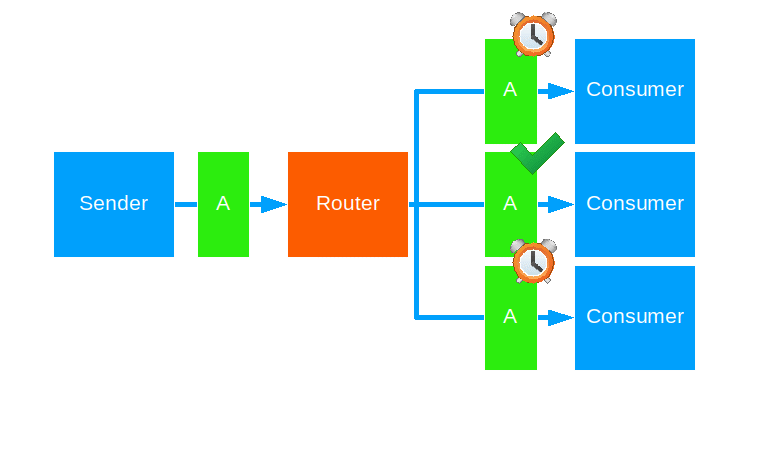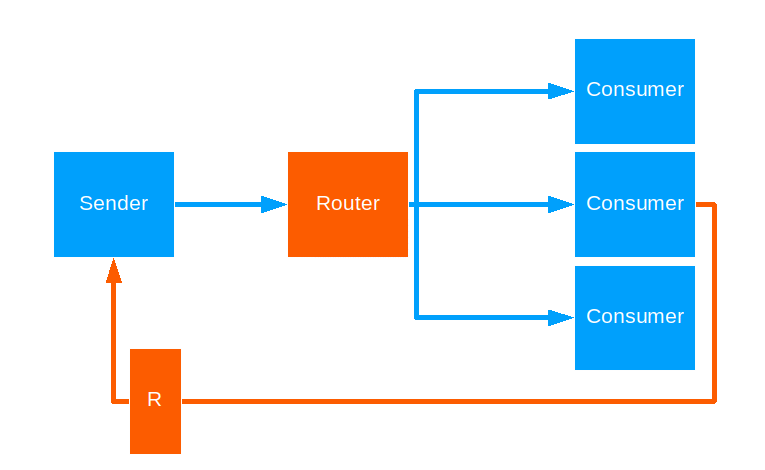
Use this when Tail Chopping isn’t brute-force enough for you.
Notes:
- Any replies after the first one are ignored.
Smallest Mailbox
This strategy forwards each message to the routee with the smallest mailbox.
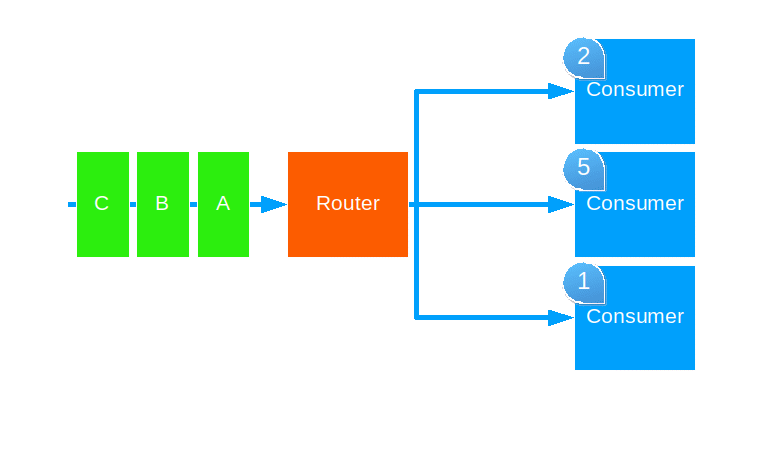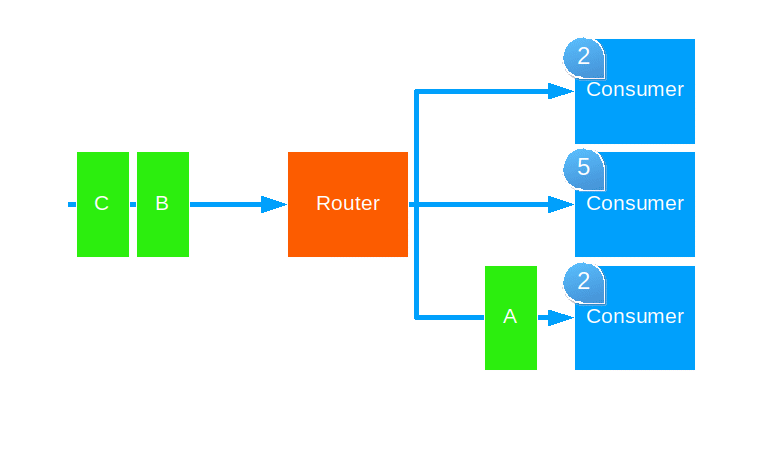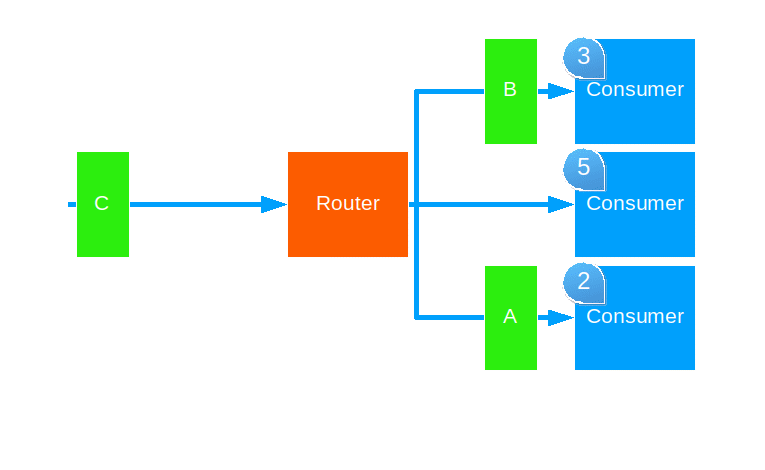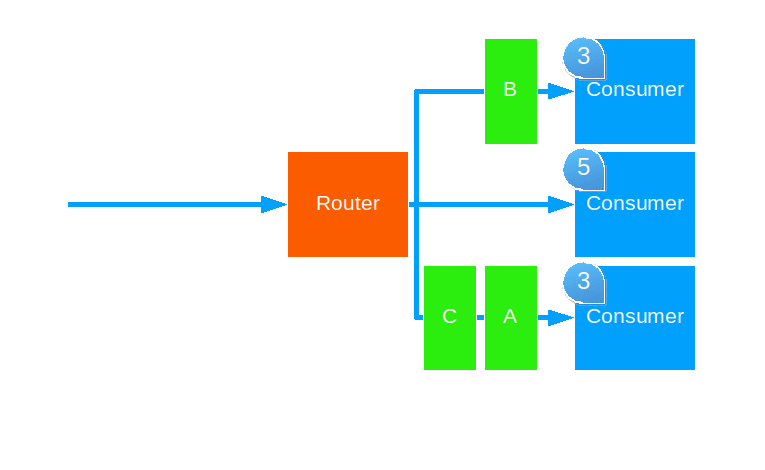
Use this when attempting to balance equal load across different capacity hardware. This strategy only works will pool routers, though it works across cluster nodes.
Prioritization is as follows:
- Routee with empty mailbox and not processing a message right now.
- Routee with empty mailbox regardless of processing a message right now.
- Routee with lowest inbox message count.
- Routee in a remote actor system.
Automatic Resizing
Pool Routers can scale out and back based on load. This enables the actor system to adapt its responsiveness to tolerate under heavy load without letting a flood of requests overwhelm it outright.
Example:
var resizingRouter =
system.ActorOf(
Props.Create()
.WithRouter(
new RoundRobinPool(10)
.WithResizer(
new DefaultResizer(
10, /* lower bound */
100 /* upper bound */
)
)
)
);
Stashing
Stashing allows an actor to put away the present message for processing at a later time.
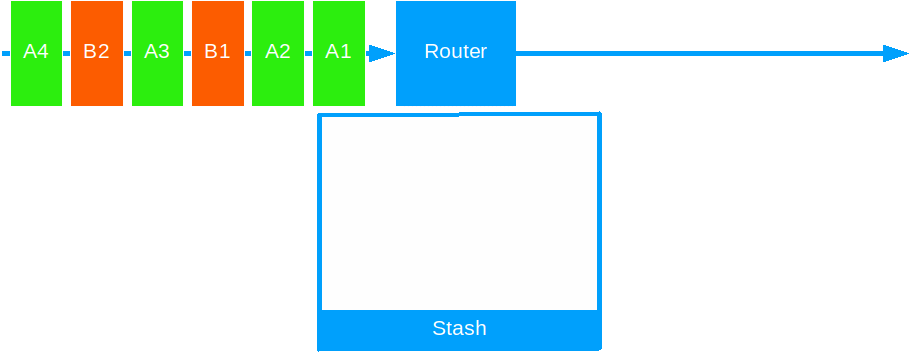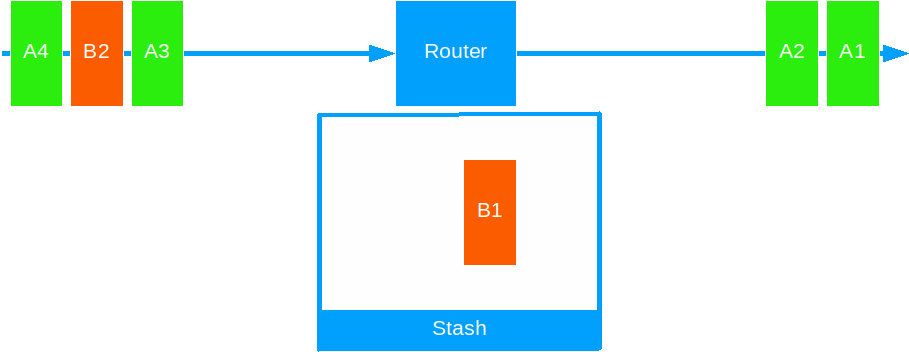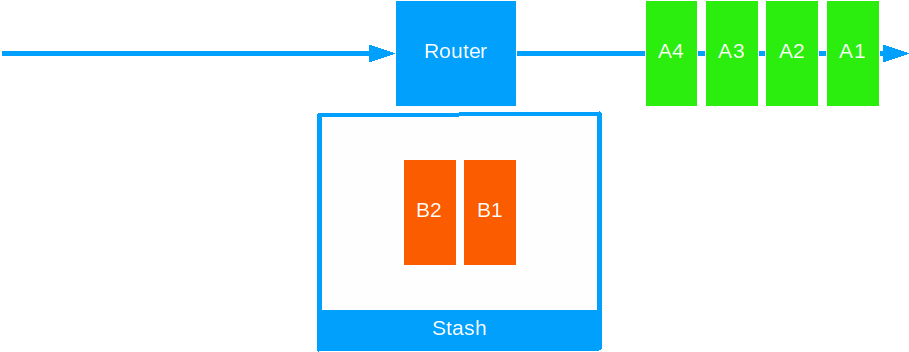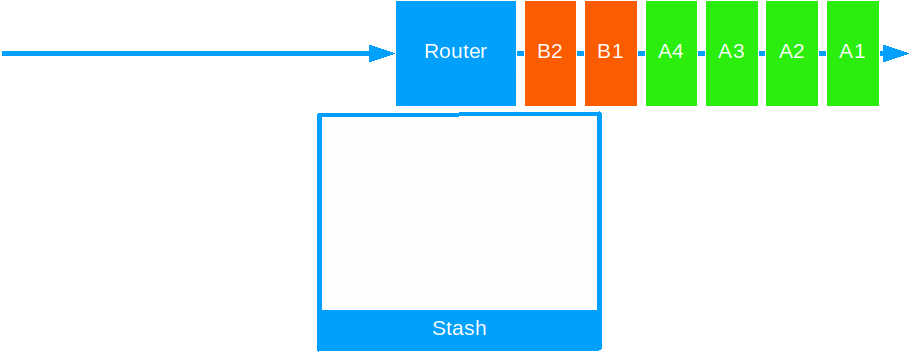
Use it to prioritize certain messages over others, on a particular criteria, or to delay processing on external systems.
Stashing can help with:
- Improve system responsiveness by prioritizing high-importance or fast messages over low-importance or slow ones.
- Improve system resilience by holding on to messages that require work on an external system, while the external system is down or recovering from a crash. Extra useful when combined with a Backoff Supervision Strategy.
- Optimize capacity use of external systems by limiting throughput of certain messages during certain times of day.
Stashing works in two steps:
- Stash the current message: This puts a message on a temporary store - a list of messages, ordered in the same way they came in.
- Unstash one or all messages: This puts all the stashed messages in front of the queue, in the same order they came in.
Notes:
- Unstashed messages keep their original delivery order, regardless of unstashing one by one or all at the same time.
- Unstashed messages are inserted at the head of the inbox and will therefore take precedence over any normal messages already queued.
Example:
using System;
using System.Threading.Tasks;
using Akka;
using Akka.Actor;
public class SomeStashingActor : ReceiveActor, IWithUnboundedStash
{
public IStash Stash { get; set; }
public SomeStashingActor()
{
// request a wake up every second
var today = DateTime.Today;
Context.System.Scheduler.ScheduleTellRepeatedly(
TimeSpan.FromSeconds(1),
TimeSpan.FromSeconds(1),
Self,
ProcessHeavyMessagesNow.Instance,
Self);
// process light messages at any time
Receive(m =>
{
// do a little work here
Task.Delay(100).Wait();
});
// stash or process heavy messages
Receive(m =>
{
// check if we can we process a heavy message right now
if (InPeakTime())
{
// stash the heavy message for future processing
Stash.Stash();
}
else
{
// do lots of work here
Task.Delay(1000).Wait();
}
});
// unstash all heavy messages for processing
Receive(m =>
{
// check if we can unstash now
if (!InPeakTime())
{
// good to go now
Stash.UnstashAll();
}
});
}
private bool InPeakTime()
{
var now = DateTime.Now.TimeOfDay;
return now >= _peakTimeStart && now < _peakTimeEnd;
}
private readonly TimeSpan _peakTimeStart = new TimeSpan(6, 0, 0);
private readonly TimeSpan _peakTimeEnd = new TimeSpan(21, 0, 0);
private class ProcessHeavyMessagesNow
{
private ProcessHeavyMessagesNow() { }
public static readonly ProcessHeavyMessagesNow Instance = new ProcessHeavyMessagesNow();
}
}
public class MessageThatRequiresLittleWork { }
public class MessageThatRequiresLotsOfWork { }
Blocking
Blocking an actor on long running operations can and will degrade throughput.

Long running operations can happen when dealing with I/O, external system calls and even calling and waiting for replies of other actors.
Blocking an actor thread on operations such as these will limit message throughput by:
- Making the queued messages wait to start processing.
- Making the blocked thread unavailable to process other work.
There are a couple of Akka-friendly ways of handling this…
ReceiveAsync
Use ReceiveAsync coupled with an await/async handler to free up the thread while processing.
Pros:
- Guarantees message completion order.
- Frees up the thread during the
async/awaitcontext switch. - Enables use of a router to limit parallel calls to an external system.
Cons:
- Requires the use of a router to scale out at all.
- Queued messages will still wait for prior ones to complete before even starting.
- Pays an overhead cost for the async/await context switch.
Example:
using System.Threading.Tasks;
using Akka.Actor;
public class SomeAsyncActor : ReceiveActor
{
public SomeAsyncActor()
{
ReceiveAsync(async m =>
{
// perform some work on the external system
await Task.Delay(1000);
// ack the sender
Sender.Tell(WorkComplete.Instance);
});
}
}
public class MessageThatRequiresExternalSystem
{
}
public class WorkComplete
{
private WorkComplete() { }
public static readonly WorkComplete Instance = new WorkComplete();
}
PipeTo
Use PipeTo() to pipe the result of some background work to either the current actor or straight to a target actor.
Pros:
- Frees up the thread without paying for
async/awaitoverhead. - Scales out without a pool.
- Queued messages do not wait for earlier completion to start processing.
- Can send the result straight to another actor in the background.
Cons:
- Can scale out too much and overwhelm an external system.
- Does not guarantees message completion order - that depends on the external system doing the work.
Notes:
PipeTo()works with any TPL Task;- Therefore, one can
PipeTo()the result ofAsk();
Example:
[code language=”csharp”] using System; using System.Threading.Tasks; using Akka.Actor;
public class SomePipingActor : ReceiveActor { public SomePipingActor() { Receive(m => { // capture the original sender for piping var sender = Sender;
// perform some work on the external system
// and send the result to self
// this does not block the thread
Task.Delay(1000)
.ContinueWith(t => new ExternalSystemResult())
.PipeTo(
// target - can be self or some other actor
Self,
// sender for the message
// using the original sender here to make things easier
sender,
// optional - factory for a success envelope
// we can use it if we want to add additional information
wr => new NotifyExternalWorkCompleted(wr),
// optional - factory for an error envelope
cause => new NotifyExternalWorkFailed(cause)
);
});
// handle notification that the external system work completed
Receive(m =>
{
Sender.Tell(WorkComplete.Instance);
});
// handle notification that the external system work failed
Receive(m =>
{
Sender.Tell(WorkFailed.Instance);
});
}
private class NotifyExternalWorkCompleted
{
public NotifyExternalWorkCompleted(ExternalSystemResult result)
{
Result = result;
}
public ExternalSystemResult Result { get; }
}
private class NotifyExternalWorkFailed
{
public NotifyExternalWorkFailed(Exception cause)
{
Cause = cause;
}
public Exception Cause { get; }
} }
public class MessageThatRequiresExternalSystem { }
public class WorkComplete { private WorkComplete() { } public static readonly WorkComplete Instance = new WorkComplete(); }
public class WorkFailed { private WorkFailed() { } public static readonly WorkFailed Instance = new WorkFailed(); }
public class ExternalSystemResult { public Guid SomeResult { get; } = Guid.NewGuid(); } [/code]
Serialization
Pushing messages through the network makes you pay three-fold:
- The sender must pay CPU time to serialize a message.
- The network must pay transfer time to transfer all the bytes in the message to the receiver.
- The receiver must pay CPU time to deserialize the message.
All the above add up. You can therefore improve message throughput by using message serializers that reduce the metrics above.
The most common serializers in Akka.NET are:
- Newtonsoft.Json: The default Akka.NET serializer for user messages as of writing.
- Hyperion: Scheduled to become the default serializer for user messages from Akka.NET v1.5+.
- Google.Protobuf: Akka.NET uses this for optimized internal messages but not for user messages.
This is how they compare:
| Properties | JSON | Hyperion | Protobuf |
|---|---|---|---|
| Human-Readable | Yes | No | No |
| Version-Tolerant | Limited | No | Yes |
| Platform-independent | Yes | No | Yes |
| Payload Size | Baseline | Smaller | Smallest |
| Supports POCOs | Yes | Yes | No |
| Supports Complex Object Graphs | Limited | Yes | Yes |
| Requires Specialized Development | No | No | Yes |
There are others as well, which are similar to one of the archetypes above, though varying in unique development features and performance.
Less Bytes More Game
When it comes to maximizing message throughput, human-readability is an afterthought - with the notable exception of your message destination being a scale-out JSON document store to begin with.
After your storage systems and external systems, your slowest resource is often the network. The less bytes on the pipe, the faster a message can arrive at its destination. If the destination is a persistent storage system, the less bytes there are there to persist, the faster they can get persisted, of course depending on system specifics.
This, among other reasons, lies behind the plan to switch to Hyperion for user messages
So this becomes a no-brainer:
- Use Hyperion by default for messages where performance is not critical or for fast solution prototyping.
- Use Google Protocol Buffers for message transfer or persistence where performance or version tolerance is of critical importance.
As Google Protocol buffers uses its own syntax and compiler, it will require additional build setup and development time than using POCOs with Hyperion. However the investment you make in time, you will get back in increased performance numbers.
Switching To Hyperion In Visual Studio / .NET Framework
Run this on the NuGet Package Manager Console:
Install-Package Akka.Serialization.Hyperion -pre
Hyperion is formally in pre-release status at the time of writing, hence the -pre flag.
Now apply this to your application’s hocon files across all the nodes in the cluster:
akka {
actor {
serializers {
hyperion = "Akka.Serialization.HyperionSerializer, Akka.Serialization.Hyperion"
}
serialization-bindings {
"System.Object" = hyperion
}
}
}
Switching to Hyperion In Visual Studio Code / .NET Core
Run his on the terminal:
dotnet add package Akka.Serialization.Hyperion
Hyperion is in pre-release at the time of writing. If it is still in pre-release as you are reading this, then the command above will fail. That’s fine. Take note of the nearest package version that the error states and run the next command, replacing the version below with the version you see in the terminal:
dotnet add package Akka.Serialization.Hyperion -v 1.1.3.31-*
Now apply this to your application’s hocon files across all the nodes in the cluster:
akka {
actor {
serializers {
hyperion = "Akka.Serialization.HyperionSerializer, Akka.Serialization.Hyperion"
}
serialization-bindings {
"System.Object" = hyperion
}
}
}
Using Google Protocol Buffers
This requires a tutorial of its own, and is out of the scope of this article.
You can start with the tutorial for C# to understand how Protocol Buffers work.
Thanks
As you can see, Akka.NET has several tools to aid you in maximizing message throughput in your actor system. The sky is the limit. Or your network. Whichever bottlenecks first.