
How To Selectively Update Complete Duplicate Rows Using T-SQL
This could be an interview question actually. How are you able change, say, only one out of an arbitrary collection of complete duplicate rows, and in a set-based manner?
Of course you could ask why do we have duplicates in the first place, but that’s another matter altogether.
The Problem
So for example, how would you change this:
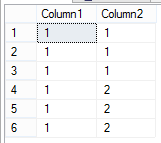
Into this:
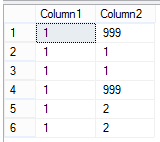
And if you run it again, into this:
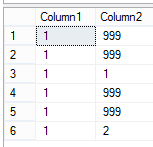
Well, after auto-suppressing the auto-immune response to having duplicates in a table, a few options come to mind:
- Do it by hand. Like, with your fingers.
- Use a
CURSORto identify the rows one by one. Brrr, shivers. - Add an
IDENTITYor some other artificially unique column to the table, so you can identify them. - Dump the whole data into a working table with a unique column, do some operation there and refresh the data back.
- Use the
UPDATE-@Variable-FROMsuper non standard T-SQL gimmickry. - Use a loop with
UPDATE TOP 1. - Say lalalalala, I can’t hear you, while you cover your ears and close your eyes.
- Use the non standard
UPDATE FROMpattern with a window function in there somewhere.
Hmm, I have the very slight impression that 1 would be awfully tedious. So let’s leave that one for later.
2, besides not being set-based, it tends to cause allergic reactions in good T-SQL developers, so let’s keep that aside.
3 would alter the database schema just because of one (really odd) operation, so let’s pause it for a bit.
4 is probably overkill for a table of 10M rows.
5 is unfortunately a RBAR operation too and we all need to go home and sleep at some point.
6 is a RBAR too, sadly.
7 usually gets you fired so maybe not a good idea.
That leaves us with 8, the UPDATE FROM statement. True, it might not be standard, but, it is set based… and can update rows located in a SELECT statement, regardless if they are unique or not (unlike his friend MERGE who is not too keen on it).
So let’s try that one today.
Step 1: Create a sample table to test this out
Before trying some crazy gimmickry in a production, it’s usually a good idea to test your stuff somewhere else. So let’s create a new table to support this tinkering.
CREATE TABLE SomeTable
(
Column1 INT NOT NULL,
Column2 INT NOT NULL
);
GO
Step 2: Create some fake data
Let’s just create a couple of rows to test the theory quickly.
INSERT INTO SomeTable
VALUES
(1, 1),
(1, 1),
(1, 1),
(1, 2),
(1, 2),
(1, 2)
;
GO
Step 3: Identify eligible rows
Now the fun begins. The first step is to look at all the rows in your table and identify which ones (or group of them, since they’re duplicates) are eligible for the update process.
After that, you find the groups of duplicate rows and you add a temporary column so you can tell them apart.
For this example, we’ll use the ROW_NUMBER() window function in T-SQL, but you could use your own logic here too.
SELECT
Column1,
Column2,
Discriminator = ROW_NUMBER() OVER (
PARTITION BY Column1, Column2
ORDER BY (SELECT NULL))
FROM
SomeTable
At this point you can add a WHERE clause to filter the ones you actually need.
Step 4: Identify the ones you actually want to update
And now you apply your criteria to pick the ones, from the duplicates within each group, that you wish to apply the update to. In this simple example, we’re merely picking the first identified row from each group, so the below will do fine.
WITH EligibleRows AS
(
SELECT
Column1,
Column2,
Discriminator = ROW_NUMBER() OVER (
PARTITION BY Column1, Column2
ORDER BY (SELECT NULL))
FROM
SomeTable
)
SELECT
Column1,
Column2
FROM
EligibleRows
WHERE
Discriminator = 1
This code identifies the set below:
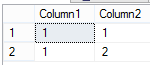
Step 5: Run the UPDATE
All that’s left now is to run the update logic we have in mind. For this example, we’ll just update one of the columns to 999. Why? Well, because video games are cool.
WITH EligibleRows AS
(
SELECT
Column1,
Column2,
Discriminator = ROW_NUMBER() OVER (
PARTITION BY Column1, Column2
ORDER BY (SELECT NULL))
FROM
SomeTable
),
IdentifiedRows AS
(
SELECT
Column1,
Column2
FROM
EligibleRows
WHERE
Discriminator = 1
)
UPDATE IdentifiedRows
SET
Column2 = 999
FROM
IdentifiedRows
If you look at your table now, you’ll see the expected result (as far this ultra simplistic example goes):
Step 6: Make sure this wretched trickery actually performs well.
And I’ll leave this one to you.
When applying this pattern to your own table, make sure you take a look at query plan and see if your initial selecting criteria (the first CTE) is well defined and supported by an index.
After that, the filter on the ROW_NUMBER() (if you’re using that at all) will most likely generate a SORT operator, so you’ll want to limit the rows that go in there if you can.